Enabling technology - Missing pieces Douglas C. Engelbart. 1.* - unedited transcript - Marcelo Hoffmann, advice for Colloquium participants Thank you, Marcelo. You know, this whole colloquium has been planned since last spring and none of us appreciated what it would involve in coordination and effort. And it seemed like a good idea that we would open our own repository and then ask for things and then we get flooded, so all I want to say is if you contribute into the dialogue and aren't getting any response, please don't get discouraged. We have to muster the resources and people but it's one of the goals of this whole event to see if we can make something real happen like that. And as I'll say over and over again, if I have my head clear during this whole colloquium, how to build and run a really effective dynamic knowledge repository is something that I don't think anyone knows what it'll take to do it. And the first time when people get one really working at any significant scale at all it may cost about 20 times what anyone would believe ought to. But that's the whole engineering approach, to get in and do it. And I don't think that any kind of research is ever going to do it other than actually building it, making it work. Anyway, so I think the whole thing about this worldwide bootstrapping is something that makes the journey to the moon look like a Boy Scout trip. [chuckle] Some people accuse me that I make things sound so big that when I fail, I have a reason. [laughter] So why didn't I think of that? All right, let's get going with our session 4.
The orientation
here is about technology, but what I'd really like to do is scale up and
down about the involvement and impact of the emergent technology within
and upon society's augmentation systems. Now I just kind of wanted to kind
of quickly look at that and then do kind of a conceptual overview, the
best I can call it an architecture of the environment of how people are
sort of going to work with the technology there, and then be working towards
a takeoff position towards what this kind of push could be and we have
some really interesting people here that can come on and talk to you today.
And incidentally we have some visitors here today. There's a really good
friend of mine, Marlene Mallicott--she's the significant other of Ted
Nelson, if you ever heard of him. And I charge her with getting Ted up
on his feet for the past ten years. A great gal, and she's sitting up there,
blushing. And then next to her are two people from Australia who are long
time associates of Ted Nelson's working too. And I'll introduce a couple
of other people later on, but I wanted to especially say hi to Marlene
and her buddies.
Ok, there are a lot of experiences that have molded me, hammered me,
etc over the years and I've repeatedly told you about the impact of prevailing
paradigms on how the world sees and hears what you say, it's really interesting,
so there's a lot of experience and publications, and there are some really
effective ones on the web, and I'm going to give you some snapshots of
those so you can get a chance of going back in there with it. And then
the general images of what this CoDIAK process is, the Concurrently Developing,
Integrating, and Applying Knowledge. The name sort of developed because
just calling it collective IQ or repository didn't indicate what we're
really talking about are the capabilities involved in doing that. So that's
what the CoDIAK acronym stands for, it's the set of capabilities that seems
critical. And it may be we have to somehow introduce more terms than concurrent
and development and integration and application in order to be consistent
about it, but it was just a name that did some good.
So this open hyperdocument system that we talk about more and more today in here is sort of the way to focus on the emergent technologies that will provide the kind of support for CoDIAK that we're talking about. And in the end we'll integrate a lot of the things that Ted has done and what a lot of other people have produced and there's no way in which we talk about is the claim that this is the path. What we're talking about is getting a start with the kind of things we've had experience with and know and using some of the up to date kind of environments... but really the big concentration on getting it started in an environment that will somehow promote the rational evolution of it and that sort of goes along with that there are no monopolies in that environment. And that all kinds of little niches will form in which evolution of some of the social organisms will start taking place. The thing we think to do for that environment is to give it the maximum visibility for every social organism about what's happening out there so that it can sort of decide and guide its own evolution and walking like that. That's the best we can do so that's why the thing we talk about is the very first important dynamic knowledge repository would sort of have that purpose in there. So if it ever gets going and you guys have helped, you guys can go on feeling more satisfied about your career, I'm sure. Anyway, so I had brought you these concepts and when the research money dried up in the mid 70s, I got gently find that there were no more funds and SRI couldn't support us with its money, so they would have had to sort of jump the whole system and everything, but a lot of the people got a chance to get jobs at Xerox park but there were 20 some or more who weren't available to that. And we were actually managed to get it auctioned off, this NLS system, to a commercial company in Cupertino called Tymshare [pronounced "timeshare"] and they were one of the one of the very earliest producing timeshared services. And they had their own network around the country; it was slightly different from the AARPAnet. But then they got enough funding to sort of merge so that we could be the gateway between them so they acquired our stuff from SRI--so then we had an interesting six years from 78-84 there. And then McDonnell-Douglas, in a spurt of sort of mad optimism decided it was going to get up a whole business in the information services area so they set up an information services group and acquired a $1 billion revenue worth of acquisitions to do it and down in there was Tymshare and down inside Tymshare was our little group, which was horribly named the office automation group--you know how I hate the term automation. But what this provided was a very interesting and important thing for me, that I could walk into McDonnell Douglas as a cousin, rather than some vendor and start understanding and making friends in there, and it was just extremely good. So there was a subset of people in there that got all turned on to what we were doing and we actually got some prototypes. Meanwhile the commercial side was getting customers, building up around the country till there were some 20 or so mainframe servers around the country supporting people, and an Air Force group really started trying to see how they would really go after integrating their office automation and communications among all the airbases in the world. So they had 5 of their mainframes on their site in Illinois, and were doing things with knowledge management and etc that were very advanced. And so it would be interesting during all this time to convey enough of the details of what our system could do in order to show you the kind of unique things that it would do. So we're not going to get there now but there's a lot of background in that. And one of the really important things was that the corporate vice president of information services at McDonnell Douglas, we kept pushing his doorbell and he finally said, "I'll five you a chance; if you can go get this group of people here" and it was this group doing a multi-corporation study about very high altitude advanced aircraft thing that would fly at a hundred miles up or something like that, then I'll really listen. So about a year later we came back and said, "Well, they're interested and they're doing their project management stuff with it, and they're as excited as hell with it and so on, and that was the point where he said, "Well, I'm sorry, but I really don't think that we ought to be in that business. Besides, when I talk around, I find that IBM and DEC and Hewlett-Packard don't know anything about this link stuff..." It was too radical. But the lesson learned--if you're going to get a big project, like an aircraft, that's got several thousand people in the major contractors environment working through all sorts of divisions in the place, and then there's something like six thousand supplier companies out there, a hundred or so will have to be closely involved in the design of that thing, with the specifications, the exchange, the requirements and all that. And you look in there and you say, if the kind of collective knowledge work and the exchange etc that we're talking about have got to take place, the standards for how the knowledge containers are made and how you could interlink between them and follow things and portray it all is much different from thinking that they'd buy from whatever vendor they find interesting. So we started trying to talk among the corporate people that we could
find about something we called the open hyperdocument system. And we ran
into a problem pretty soon that some were accusing us that McDonnell Douglas
wanted to get a corner on this and it wasn't. So about then I decided I
could take early retirement and Christine and her husband helped set up
the bootstrap institute. We said, let's raise the flag and see if we could
get the world going. So that was 11 years ago and it's been floundering
and getting interested in its various ways. And all through that this open
hyperdocument system and the open standards it would have to be it would
have to be something that could evolve much more organically than the way
it does if you're all depending when vendors are coming out with their
hottest thing. And about a year ago I heard about the Open Source Movement
and I said, it's exactly the kind of thing; you really need to get the
people involved in the proactive use of it to get involved in the evolution,
so this has been the plan. So as we talk today about some of the technology
thing, it's that OHS sort of thing that's in there behind it. And it may
sound sort of silly when we sit here and we don't have the world organized,
we don't have the big vendors or anything behind it, but it's just a clear
picture that he people who get involved say, yes it's just what has to
happen so how do we get it to happen?
So anyway, that changed my perception and like I say here in this slide I'd probably bore you with it but please bear with me and let me come back and tell you some more. So anyway just about the standards, there are 2 areas in the tool systems development that seem mutually and basically important about standards. One is the unambiguous description, naming and usage of properties of our knowledge containers. There have to be standards in there, there just have to be that you can pass the knowledge containers around and there are standard ways to represent the standards and properties that you are going to have in there. And that's what the WWWC and the XML movement are going to do about it. So we are totally pleased to have John Bozak here with us, who's the guy that really got the XML thing going, so he blesses us with his interest and appearance. Is here hiding in here someplace? Oh yeah. He's a little bashful The second one is unambiguous name, descriptions, etc for the functions
--the naming and usage of the functions that you can apply to the knowledge
containers as you want to navigate them and look at them and certain things
and massage them shape them, put them away, study, access, control, etc,
and so those have to be standard and the nomenclature has to be the same.
We just can't let it be that one vendor calls such and so one thing and
another vendor calls it another thing, so it's the same way in the shop
environment in the real world that drill chucks and shafts and tolerances
and material quality etc all have standards on them that have to be there.
So that's the kind of thing too that the tool system functions. So in this
tool system there's this combination of how the knowledge containers are
structured and indexed and properties in them are clearly standardized
and also what are the things that you can do with them. So this is a very
clear kid of environment in the evolution that has to take care of all
that.
So then vocabulary raises his head there has to be some standard dictionary or glossary about the tool systems in the world in whatever language that they are they'd have to have the same meaning. So verbs and nouns, things like that, or the objects you see on the screen when you're doing that. Well these are so-called related objects that are in the knowledge containers and what are the verbs and what can you do it about it. So those have to be clearly more and more standard so we can start talking about it. And the vocabulary must become more and more consciously evolved and must be in the hands of the end users which standards groups today not very in the hands of end users, that the vendors who are trying to push them out are in their eagerness to get out there in the marketplace and really get them settled--but boy, how they're going to impact the way the usage goes in the end-user organizations is just very critical. PAGE: Workstation history and the augmented knowledge workshop or http://www.bootstrap.org/augment-101931.htm So how do we get an environment for evolving for this thing is very critical? So anyway going back in our history, there was a very interesting paper that I gave once in a conference in 1986 and was published in... huh... how could it be published in 85 if I gave the talk in 86? I just didn't realize how far advanced I am. [laughter] anyway, so this paper is online and it's also in our augment journal - we give a number there - so in augment we can just jump to 101931 booms and then we get a view like this. But this is more of a history and a chronology of events and it goes through year by year the kind of things that emerged and the experiences we had and it's really important to get a glimpse of where we came from. PAGE: Knowledge domain interoperability and an open hyperdocument system or http://www.bootstrap.org/augment-132082.htm And then in 90, I published a paper called the Knowledge-Domain Interoperability and an Open Hyperdocument System [www.bootstrap.org/augment-132082.htm] and that's where this clearly came out and tried to draw a picture in that. So there's a lot in that particular paper so all these e are there by the same URL that's at the top right there. That'll be on the slides that you can get access too later. PAGE: Toward high-performance organizations: A strategic role for groupware or http://www.bootstrap.org/augment-132811.htm And this is a more recent one in 1992 where we're really trying to talk about things like the ABC model and CODIAK and the Open Hyperdocument System and the general groupware so there are basic properties in there that talk about things like saying, look it would be ridiculous if you don't have integrated editing and browsing in whatever tool you're using, that you move over to one to browse and then go to another to edit. That editing and generating and working on documents is a mixture of moving, shaping, viewing, and massaging, so that the environment we had was just so integrated you were just using the linkage and addressing and stuff by the minute. So you can just ask Dave Casper about the stuff... where did you hide? ...
These papers give a lot of good background. And then this is a way f looking at it with a modern version of our augment thing that we have, I just entered there and looked at one particular view, one line only at one level group of the sections in there about mixed object documents, explicitly structuring, view control and all of that, and view control is so important
So this is just various views such as Augment itself gives it. And it would be really interesting to demonstrate some of the Augment features but the particular medium that we're working in can't really handle the dynamics of that and that would be someday interesting.
So with that sort of background we come to one of my favorite portrayals and you might remember seeing this just about once every session but for me it is just such an important starting place, it's like saying, "Hey look, down here there are things you're born with, basic human capabilities and those get augmented by a whole array of things and as you gradually learn to use the different things, the language customs, the procedures and the tools and the facilities you gradually acquire a capabilities infrastructure that is really competent. I used to call it a capability hierarchy until it finally dawned on me. I was giving a talk about this in a group and one lady politely raised her hand and asked me, "That's not really a hierarchy, is it?" And, "Oh, that's right." So it really pays to give a lot of lectures so they don't really know how much each one is adding to your knowledge. [laughter] But the concept of that infrastructure is just really important like that, that every ability is at some level dependent on the lower-level capabilities and that a lot of the lower level ones are involved in the higher level ones and down at the very bottom are these very basic human capabilities, sensory, perceptual, cognitive, and motor. And it is very important part of the mental thing too is the unconscious part that you aren't aware of. And yet so much of what we think about doing today, we're ignoring what that unconscious can do. When I'm driving in heavy traffic, I just think, God, there's a lot of stuff that I'm not aware of where the judgment decision comes from, whether I'm going to worry whether that car is going or not. Just one look and I don't know what I use to gauge it, but we're depending all the time on things like that. Later on I'd like to talk more about the thing in here where we say if we have a very different medium with which to do our communicating with the world and different things that can do sensing and triggering our sensory things etc then we can have a totally different sort of environmental interface that we can adapt to and then we'll start realizing that the way we do things now and our assumptions of them are based on the environment we grew up in. And the language we use evolved in noisy, different kind of environments of all sorts of things so the very way we choose words and express them and how long it takes to do it and how much time we give the listener to adapt to it and the environments all evolved in that sense. So you can say wait, I can have an interface that can be a much crisper, sort of thing with much clearer ways to express things and feed them back. How can I then start connecting what machinery I've got here [points to head] and the outside world? And that image has been with me since 1960 saying, that's what's there to go after. So how do we get changing the paradigm a little bit of the sassy to learn and natural world of today, saying it's easy to learn for people with the backgrounds that we've had, and it's natural to use when you learn how to use it that it's not that much different from what you've been used to, so you've got to evolve a way. So the way that you bring in and introduce evolving tool systems in the world has a big effect on what the evolutionary opportunity is. So I'll get back to that later but it gets very irritating and irksome to some people who want to start doing something and I say, oh but! We can do it this way we can have this long-term evolutionary advantage, and we need every advantage that we can get. So something we were talking about before is if we take this and really realize the tool system and too system are definite systems within themselves and they are intimately intertwined within this capability infrastructure, the interdependence is very high, you can't come and just make significant changes in the tool system it's just going to change the capability around in here which is going to change the requirements in the human system. In order to take advantage, you just got to go. So this picture holds for one individual like you, but also holds for whatever team you're with. So with almost any social organism there is you can look at this model and say, Jesus, readapting that infrastructure upon those interdependent social organisms and institutions we have out there and they're all simultaneously going to start evolving at rates that they haven't had before. And so that co evolution of all of that is going to be a big challenge and have to be recognized, so it's not really just the co evolution between you and the tool you're using, it's the co evolution between you and the organization you're working in, and the co evolution of that organization and its external environments and on up the line. It's the co evolution of governments, humans, and nations. So when you talk about strategies, it's thinking about any chance of having a valid way to go after that kind of evolutionary thing in a sensible way, so it really deserves careful attention to that strategy.
So then we say if you look at very simplified tool system as it evolves
in the world and the human system as it evolves, it gives you this very
crude two-dimensional picture. [Slide: Outposts on the Co-Evolution Frontier]
And when we say crude, we say that each of these dimensions here is in
itself a multi-dimensional thing. And the space out there is many dimensions
and many paths out there through it; some will get all tangled up and some
will be more successful than others, so it's a complex thing. And somebody
asked me about this little elephant or whale-like thing like this and I
said, if I went around the world and took each society and plotted how
does it fit with how far advanced it is in using technology and how far
advanced it is in evolving its human systems side, where would it fit?
And I just hypothesized that the group of them would make a cluster of
that shape. And that was when the margin for tools that we could foresee
was about out here and so we were always creeping towards something like
that where we could see and say in twenty years, where do we expect the
margin to go? And we went on to present in earlier presentations that the
rate of which technology is exploding today, our boundaries out there on
what the technology will be able to do, that we need to start planning
for them and to start thinking. It's a hugely expanded frontier. And in
20 years, wow. So it was much more of a picture of this scale e of a frontier
and what we didn't have was where we wanted to get outposts, groups of
people who have moved out there and have learned how to live. And it's
something that we're going to talk about over and over again, about high-performance
teams. That this is what my recommendation for how you go about getting
outposts. And what about those high performance teams, how are they going
to do you any good. And it's not the kind of thing where someone lives
in a dome and is all isolated and shows what they can do for this time.
These people, to really be effective, they have to be out there in what
they can do and how they work together but they have to be part of the
ongoing social structures of today in order to be real life and in engineering.
So that means what kind of tools can they have that are way advanced out
here so they can work in the same environment, well that comes right back
to the kind of knowledge containers they can use. You can push ahead with
characteristics that your knowledge containers can hold which are beyond
what the more pedestrian users of the day would employ but the high performance
ones can really zing and work with it. And if they can work on the same
knowledge domain s as the people then they're there for people to watch
and say, God, how did you do that? In that little time you just flipped
these views and boom. Well, it's just the way, if you just ask for those
kinds of views and learn how to crock it all quickly and at the same time
you're reaching around to grasp the most significant ones and you got an
idea for where you want it to go so you preset your launch and it goes
up. Well I don't understand what you're saying, but how can I learn? Well,
you're only a grade 4 pedestrian now but this is grade 8b level stuff but
you can work on it and you'll get it in a couple of months and stuff. So
I can't imagine any other evolution sort of thing other than that. So when
we're looking for a way to start implementing an open hyperdocument system,
this has been the kind of thing it is. So by the end of the day we give
you the feeling for the potential for what's there today to get started
on that.
The high performance team is very important like I said and they can
use special tool and human system enhancements but are operating over the
same
knowledge domains as everyone else. [Slide: Important strategically to
cultivate high-performance teams.] And their capabilities are visible to
the people around them. So we had things like that back in the 70s, this
shared screen thing, where somebody who was a trainer or supporter, someone
who was having trouble called them up and they'd say, 'Let me see your
screen' and then bang, so now I see what's on your screen. Oh, that's what
you're doing, well just pass me the controls and I'll show you what you
can do. So they could actually adopt the whole range of tool capabilities
a person had to show them how to do it. But also the system that I'll show.
... So, looking at some of the basic human capabilities was kind of
important for us, and what we do now today as I mentioned evolved a very
different environment from what's going to be in the future, so we need
to question every aspect of custom and skill and how we do things. So this
is sort of a bet that the professional knowledge workers of 2020 will show
definite signs of a basic shift in the way their thoughts transform back
and forth from internal to external. What's more, what would be really
interesting, is to take surveys of what people's assumptions is: what are
they going to think of us when they look back? I keep thinking, "What do
we think of when we read about the dark ages before 1300s or something
like that and I think, Jesus, dim, religious, some baron has them under
control, just a very mean life and just a dim outlook on the world. Well,
I'd be willing to bet that people in twenty years will look back at us
now in a pitying way and say Jesus, here these people were sitting on the
brink of a frontier and look what their perception of it was and they were
still messing around with their old way of thinking. So anyway, I've been
embarrassed enough and it's not going to bother me, but you kids it might
be different, see?
So anyway this is the kind of stuff that I worked with back there. I said look there are mental structures going on in your head. And then we got these concepts that we clarify and we could move the concepts in our mind and then we attach symbols to those concepts and then we have language that we can talk about and think with and etc. And there was a guy called Benjamin Whorf who did stuff in early language in America and he had a Whorfian hypothesis about the worldview of a culture is really limited by the language they employ and I thought that's really great. So I thought that the worldview of the people now trying to look in the future is really going to be limited by the concepts and etc they employ and stuff like that And views and portrayals that we've been used to a very limited set in technologies we've had in the past, the pencils and printers, and things like that, whereas the computer has so many more flexible views to convey things to us that we have yet to learn how to employ that in our basic dialogue and thinking. So here's a picture I got of saying, well, here's our basic human.
Sensory perceptions, and mental operations, and some of it's even conscious. I usually draw the conscious as a smaller circle than this because I got to be much more aware how much of what happens to us is something that we're not all conscious at all of. The real breakthrough of that came that I eat much more slowly than other people do. Now why is that? And finally I got to thinking, you know, it just take s me more chews before I'm ready to swallow. Well what makes you ready to swallow? You deciding? Oh, five chews and I'm ready to swallow? No, there's it's just something about the comfort of it, so I don't have any idea where that came from but it's a definite unconscious thing that it just s not ready to swallow yet so I'm the last one always, so it was always a great handicap in the navy [laughter]. Come on Engelbart, the ships sinking! No, I have to finish this... Anyway, so the whole set of concepts is really amazing and then the time came when they attached it to symbols, which was a huge advance for us, but then not only spoken language and gestures and etc and then it became a printed language it just--huge changes in the whole world. Well, that change is, qualitatively speaking, sort of akin to what's going to happen only it's going to be a sort of first wave, and the tidal wave is yet to hit us. The opportunities are huge for there, I'm sure. So anyway, this thing that became new in our evolution was making an external map of this internal concept structure. And so we did that with all kinds of clumsy tools at first and more and more flexible ones etc but the ways in which we employ the actual representation of verbal words etc on the paper etc was a direct evolution from that and we just have a really different possibility now for how we represent it and establish it and view it. Just very, very different.So this is a figure that I used to evolve step by step.
But this isn't the cathode ray tube over here on the left, this is the human with his sensual preceptor input and the motor output trying to operate in the world and he's got computer support with his language he's using and got computer tools and the processes and methods he employs and then he's got his open ended vocabulary for actually dealing out there. He's got to have fast concurrent control because it's very different now from just a pencil or something because wow he can fly through space and he's shipping, so he wants fast concurrent control and we worked at that and backed that. He wants to be able to manipulate the content as well as the structural relationship between the elements in there which is not just cutting and pasting but moving sections, so we added really structured files, hierarchically structured, that we can manipulate and view within the hierarchy and move with very flexibly. Integrating text and graphics, of course, allowing for in file naming and addressing, just right from the beginning saying you don't want to just be able to have a link or a URL that points to a file, you want to be able to talk about any object in it explicitly without ambiguity. So we got a whole bunch of flexible ways in which we do that, including the way in which he says, oh you keep in your name place and your directory a branch with a certain label on it, and there's a link that you're going to keep up to date all the time pointing to the latest something or the other out there and all I have to do is have my link whose specification is go to that place and take that link so in that address there's a definite place for it for taking a different link. In fact, this can be strung indefinitely in our environment. So it has a flexibility and programmers use it all the time inside their computers, they call it indirect addressing, so we had to send direct linking, so we use it all the time we keep saying, boy would that really be valuable in the world today, all right, let's figure out how we can set up a sort of structure of prototype of an OHS that can provide for that kind of stuff. So things have come together that I can tell you about, if I can stop talking so much... So anyway, computer storage, positions in the file being very important for if we want remote jumps and manipulations, generating a lot of optional views was very basic, so we only got a certain number of them at the time before we got shut off for research. And then displaying and then showing it back to your perceptual machinery, and at the same time you could show it back to other people, we've been doing it since 74. There are a lot of experiences being used, not as a demo thing at all but that was the way we worked. We were doing all our programming, all our user guides, our requirements, all our specs, requirements, communications and field support. There are more things than that too that we can talk about.
So this is just giving an example that every object in a file was addressable. The actual structure, since space in the computer was so limited compared to today that a very efficient way to do that was to have all these little cells that could be interlinked very flexibly and each one within would point to a respective set of text or graphics. So that represented the hierarchy and moving things around meant changing the pointers around here and here. So this is sort of an option for databases. Anyway, it was a very intent thing.
We made this thing called a journal, got it running in 1970. So here's the process you want to submit a document, it's going to a repository and is catalogued, so you had a document that was ready. You prepare the submittal form and in one place in there was a link to the document you want to submit and in that submittal form there are fields, like what kind of access control that I want from this, who do I want to get announcements etc about it, this supercedes some other document, which one? This document is a part of a string of documents beginning with what. Etc? So there were quite a few fields in there that were part of it and when you submitted it, boom - that document was put there in the repository and it was guarded, just guaranteed that it would never get changed. And whenever you went to get it again it would be as it was at that time. And also there was an announcement forum that went over email that went to everyone you wanted to say, Hey, this has just been journaled. And included is this link here. Click. Boom! So you never sent a document you just sent this little link. And if you had a document that was superceded, every time you jumped to it on some link before it came to you, you got an announcement saying it had been superceded. And there were even ways which you could track that any given passage in one document you could go find it in the same one and in the next one in a very direct way without having-without saying-you didn't-without rearranging structurally where it was in the document but it didn't matter you could go find it. So there are a lot of things in there that we learned to work with and we loved to build prototypes like that and the world started seeing because it really just changed the way the dialogue was going very much. And one of the changes was interestingly enough, everyone felt a little reluctant to install something on a permanent basis like that and one guy had such a hang up to it that he never, never could, he would just say, I don't know I just can't make up my mind if it's ready to be permanent yet. It was a very interesting social problem in this evolution. So what I did then, was I realized we brought out a first form of email at the same time that this was inaugurated in 1970. And so what I did was put a padlock on email; I said, the only way you're going to communicate is through the journal. You mean anything I put in is going to be journaled? Right, until we learn to use it. So we have some old journal entries on some of the old tapes there that say, "Who's going to meet me at the beer place tonight for pizza or something like this?" So sure, it got natural. And even software guys could imagine. After they had a design meeting, they'd say, okay, who's going to journal the notes and it was just a matter of course.
So it's a very important thing that we have to get involved in this and controlling the views as we said. So this just in this paper is a very important reading thing of augment provisions in there. It's in the OAD Journal, its number 2250. And this little address here says, go to branch 7 at that. And after the colon there are some characters that tell explicitly what kind of view you want in there. It says, in all the levels turn on the numbers, and show all the text in every paragraph and give a blank line in between them. So boom, that's what you'll see. So the next view says, oh, EBT, so that means I want that level and one line below only and only one line in each paragraph and one level below it. So that's what you'll see next time. So if you want the next view it says 'ZG' so that says I want to close, no blank line between it, and I only want to look at what's underneath '7.'
So bingo, that's what you'll see. So just very flexible in the kind of encoding of that sounded for Oakett(?) setter but it took me a whole weekend to design all that stuff and it was sufficient for a bit of research (?) but everybody learned it. And just especially with the way we had to control it with the left hand. Just very fast, so it made a big difference. AUDIENCE: [inaudible] Yeah, I'd like to demonstrate it to you guys sometime. How do you demonstrate it? I could just wave it at you, I guess. So anyway, that's just part of what we learned. So that's part of what got us dumped because everyone just looked at all of that and said, Good God! That's not the way to automate secretaries! But we found that we could bring in someone from a temp unit and within an hour they could be working because we could set them up with a very limited vocabulary and that's all they'd see. And then we also had this thing with external documents which, if your system is going to work, it isn't just fancy online. So as long as you have objects that are external and etcetera, hey, why not keep track of them too? So you'd get this kind of arrangement with mail, shared files, journal things that are permanent, and external documents.
So what you do is catalog them and they'd be in the same catalog. So
what that would mean is in there you could tell what's pointing to what.
So if in here you were talking about a given paper or something like that,
that citation discussion would show up in the external doc cataloging which
means you were starting to get control of the interaction and all of that
which was very worthwhile. So unfortunately I could never build up enough
enthusiasm that kept trying to get started but ended up getting drawn and
quartered (?) because either the internal software guys would never very
hot about doing some of the things we wanted to do.
Then we talked about the intelligence system that can be part of the dynamic depository and the tool system has to support it. [slide] So the external document control is just a very interesting part of it.
That part of the intelligence would have things like mail, journal files,
shared files, and ex files, and that would be all part of what you're collecting
about what's going on in the outside world that would be valuable and interesting.
And at the same time, what we called the handbook, we wanted to put together these three modules in the dynamic repository, recorded dialogue, external intelligence, knowledge product, and for many years what we called the knowledge product thing was the handbook, we likened it to saying that anyone given time is likely to online handbook can look and find explicitly the current state of some kind of knowledge, argument, issue, budget, etc is. And dynamically those things would try to be kept updated just like you trying to do that... so anyways.
So how do you do the handbook? Well that a lot of times we say if it's really the current state and you nailed it down, it ought to be in the journal, so look at that so those were our perceptions about that. So within McDonnell Douglass and all that, the thing we did for the national aerospace program, I was reading it went to work showing how inside of this they could move around inside the documents in this and how flexible it was to cross link between them and how flexible it was to make status reports every week.
And they just ended up showing how they could do it and then by the time the entire status report would come out it would link to prior status reports and other things like that and then it would automatically- they were really interested in macro systems- they would gather them together, put them together in a particular way, and then journal them. So every week there was a journaled status report that was in the golon(?) that could point unerringly to every one of the prior ones that was ever there and to any of the critical discussions that came about and boy! They just loved it. So when we got cancelled out of that, they just said, We'll do it with IBM for whatever system they had at the time. I forgot the name of it, but four guys worked on it for months and never got--pardon? AUDIENCE: Was it IMF? No, it was before that, but anyway, we began talking about an augmented
knowledge workshop.
If you look at how any effective workshop works in any industry or something
like that, you realize that there is a set of tools, and there are materials,
and materials have to come in standards too. And all the standards describe
how you're going to shape or surface or plate or something. So it's very
much to say we've got a knowledge workshop and we've got to evolve that.
And there are workshops for communities, which are somewhat different from
your private one or one for a close-ordered team. So these are things that
are there in the literature. And a workshop utility service was something
that in 1973 we started specifying. And by 1974 we actually opened up--
a research group opened up almost kind of like a commercial support service
so people on the AARPANET, which were mostly government at the time, could
subscribe and they could pay us money for the service and they could start
learning how to do it. So this was one of the things that got us into trouble
because this was not research, but boy, if you're going to climb the hill
we were talking about that's what you're going to have to do. So there
were many things that we did that were very exciting.
So these were all the things about augmented knowledge workshops--there was quite a bit of talk in the '80s about that. All of that history and orientation about the workshop thing and the co evolution, all sort of wrapped up in the approach being formulated and pictured of how an open hyperdocument system should take place.
Here's when we started thinking, here's your computer and here's your terminal and your computer may be embedded in a terminal, of course, but everything you do, with your mouse or pointer or keyboard goes into your operating system and it communicates with your application program. And if the application program wants to work on files, it uses the operating system to communicate with the files, or the outside world. So we've got those two domains out there that people are talking about, and Microsoft has got its Windows operating system and all its applications: Word, Excel, and spreadsheets and so on. And even X has its own operating system and its own language. So anyway, this is a good enough world - that's important.
But let's look that the application program has two kinds of functions: one is how it interacts with user and the other is how it does the work it's supposed to do; the front-end and the backend. So why don't we separate those?
It's easy enough to separate them, but why not just do that in an isolated package? And why not do just a general front end like this that's how we use that to interact with any of the applications.
So this was the sort of model that we've been building in our system and it's something that I really think will be important in the OHS world because in there you've got not only the documents that you're thinking of today, the spreadsheets, but you've got to work people who are modeling the complex economic systems or the complex computer aided design they're doing for all sorts of specialized domains. Those all have to be interfaced in the same way to point to things, talk about them work together... so when we're talking--uh, I just realized I was supposed to be in a certain time at a certain place in my slide presentation, but I don't know. Who's keeping my time? Where did Marcelo go? [silence and confusion, interspersed with chuckles] Oh well. [laughter] So anyway, when we ever GET to talk about that, you'll see that the formulation to me is very important. Picking out a technology that is available to do that and in really interesting ways, and we'll talk about that [later]. So the system we built was like that. We had a whole separate module we called the user interface system; and it was separate enough that it had a communication channel, called the procedure call interface, through the network, to the server. So, they could be sitting either on the same machine or on a separate one. What happened in here, taking care of all the control? Well, we had a virtual terminal controller that, depending on what kind of terminal you were, that would hook it up with a terminal characteristics file so that it could deal with your, for instance, your typewriter or 2D display or things like that and today there's a wider variety too.
And then everything that came through from that terminal, when it sort of cleaned it up so that it was user input would be passed to this command language interpreter (CLI) that would interpret what that was doing and call for support service and get that back in. WE actually had that at any given time that interpreter would attach itself to a grammar file that told it the language; what was coming down the stream and what that was supposed to mean and what you were supposed to do about it. And also to a user profile for that user that says this is how big a language this guy wants or how he wants to shorten some things or abbreviate this and stuff like that. All that led for a real evolution in the flexibility in what you were doing. So you had a very simple grammar and a very simple profile for a newly hired secretary and then the other guys would pride themselves in how rich they could get and then you'd begin to grow. So we got operations and verbs and nouns beginning to get in there. And incidentally we settled on explicitly dealing with it as verbs and nouns. And you can do that today, too; I want to group that cluster, or something. Then how you want to designate any particulate object or noun and designate what action or verb you wanted to do to it; there's lots of flexibility available in there. So that's the picture that I feel that we need to get in the open hyperdocument system too, so that you can really get evolution going on in there. Meanwhile, the standards for what's in the file can evolve to be able to keep up with being able to handle the advanced ones and the simple users wouldn't even have to know that those properties were there; there are properties in our file that some people never found out about. Every paragraph, for example, had a rec that said who changed that last and when. And everyone had an indent [ID], so it was a simple indent. Well some of the things we could do with that was filter. We could turn that on and say, I want to see only what's been changed by so-and-so, or only within a certain time. That was just because we had all these viewing options so why not? So not many other people would know how to use it, but in the software world, boy! And that was because all our software was hyperlinked and hypermedium structured like that too. So what happens? I've got a bug in something--that's funny, it was working just a month ago, what's happened? Who has been in there in the last month? So you look in there and say, Fred. He was there. Just show me everything Fred changed and we'll find the bug. [chuckle] so there are things like that that have applicability in many places, so why not make a standard provision in the file structure so that you can start doing that so that as more and more people start to learn how to employ it, they can, but they don't have to bump into it if they don't want to. This is the sort of thing that the XML extensions to HTML documents provide you with. Oh, no, we can't have questions; that would make me--we got to find more ways to do dialogues, so we'll try to do it at the end. Sorry, I got to hurry; I'm behind.
So even the way that these two user interface systems could start to connect, by 1974 the relationship our relationship was any place tying into in the environment that you wanted connected. [New Slide] So both guys are watching what this top showing user was doing. Or you could pass control so the controls came this way through it. Or you could put in 10 or 15 people and pass the controls between them and watch them. We published about shared-screen service and thought the world would be excited, but it wasn't until 2 years ago that much of that was being done in a conventional way.
And then if you've got that kind of thing, almost anyone then could learn to write command scripts. Those could be fed into the command language interpreter (CLI) and interpreted. Boy, we found that one of our women support persons who had no idea how to do accounting was working with a customer person who also had no idea and together, they kept on messing up, not telling anybody--and they had a whole accounting system in work. And they were so proud of it! And it would grind away and consume a lot of power and was very slow but it would grind away and do the work but it would do the job, so it was hard to scold them...
But all of that was part of designing a system that could evolve. The thing was we had an interface system and the conjecture was that was going to be hey, that thing could work in many application domains and you have one interface server. We were trying to do that and reach through there to other kinds of applications packages. McDonnell Douglass started talking to us about putting it into CAD systems and database and things of that sort but we got truncated. But this idea, this intermediate server. Lo and behold I found that IBM has a design plan they call the web-based intermediary; that would be called the 'WBI'--we got pictures. So the things that we wanted to do would be something like that. So a little bit later, I can't remember when, but when I get there they quit. Jim Spohrer is going to get me pictures of the WBI status, and some of the other things that were going to be involved in that, but I wanted to give you some background of the concepts--where this is coming from, that it's not just somebody just saying let's get together and build the next open hyperdocument system. We got this framework to start with and it's certainly open for a lot of evolution in it and improvement, but there's just a lot of experience out there behind it. I'm sure it'll be a very good launching thing for OHS 1 to 1.5 before everyone else with great ideas and modern evolution will be taking off and I'll be sitting out there, waving off and sort of disappeared. Or as this really interesting story goes, I must hurry because there they go and I'm their leader. [laughter] that's the way it's going to be. So you guys in the world will take this off and I'll be saying, hey, wait for me--I'm supposed to be your leader! In this sort of thing there's a special relevance to things in here;
there's this guy who sneaks in periodically into this meeting and he's
here today named Neil Scott and he's got a group called the Archimedes
Project at Stanford and he's part of this group around the world that's
really working hard to get computer interfaces for handicapped people and
things like that. So he's furnished the kind of URLs here that you can
point to.
Neil doesn't know that where I'd really position that thing, that's some of the most important research going on in the world. And it's important enough that it helps handicapped people with different kind of handicaps in their sensory, motor, apparatus where they cannot effectively use today's interfaces, so they're finding ways to do it. But what it opens a door for us is to start thinking, hey, you see someone who can't move their arms but is blinking and moving their face a little bit control the computer. And then you realize that people who are blind can sense Braille so fast that you can't believe. And people doing sign language getting ways to do signs and communicate and you just realize that you've not been aware of what people who have normal sensory and motor faculties--we just go along doing the same old dumb way that we've been doing in the past we got to start thinking about how we can extend the use of the sensory and perceptual and motor things that we've got and all the unconscious things that we can learn so we can move ahead. These guys are making outposts out there that we have to recognize. It's just extremely important. One of the things that he tells me he has is a gadget which is a total
access system that includes both hardware and software and you can get
any of the motor stuff like that and it can get it into any computer system
and pretend it's a cursor driving mouse or a keyboard actuator etc, so
that means whatever that computer's interface is whether you point and
click or type or push buttons, you can drive applications. That means that
you can put any interface you want in front of that and drive things. So
instead of going down to the side of the system where you'd like to find
a clean application programming interface that they talk about--the vendors
aren't very good about providing that--you can go back out here like and
drive it. So anything your application is capable of doing, you can do.
So that's what I think about some of the high performance teams that
got to go cleave with them for hey we've been ignoring you all this time,
but let us that interface for a while and experiment with how we can twitch
and wiggle and grunt and drive stuff more effectively.
So this is what I've been saying; how to extend our "normal" sensory
and motor facilities into more effective utilities than we can even contemplate.
That [Neil Scott's] "total access system" is something to try to get in
charge with.
Some time we should try to get Neil to tell us something, if he's not
too embarrassed. so then this IBM's web based intermediaries has some important
advantages.
We're going to get in the schedule; we can bring [Jim Spohrer] in sometime, right? OK. We had another schedule we were going to do. Well, we were about to put Jerry Glen on the spot, but we don't know where his slides are. What do you recommend, on the spot, command and control? AUDIENCE: [inaudible] Well, what are we going to do when we get to them later then? [chuckle] Ok; we'll leave it there; and Jerry Glen whom you've seen on video twice, talking about his millennium project for the UN University and he's here visiting, so he'll be here talking. You got a handheld mike? Yeah? Ok. On the Millennium Project by Jerry Glenn, Executive Director, American Council for UN University Co-Director, Milennium Project - Break - IBM's Web-based intermediaries by Jim Spohrer, Senior Manager & Scientist, USER Group, IBM Research, Almaden, CA Co-founder of the EOE (while at Apple Computer Co.) ENGELBART: ...kind of things in fair usage I'd like to stick a tune in too well. With more people here and get some dialogue going in the end. This is great.
Here's one use for WBI. So just in general, the interactions. This is the human and browser client that we talked about, the general intermediary --that's WBI--and an ordinary web server. So your client sends message 1 to the intermediary. Suppose that is what you think is an ordinary URL, says I want something. So it says okay, I know where to go and it gets there and what gets back is an ordinary HTML code for a page or something. So you could get this thing conditioned so it could transcode that so what you see is something else; that you invent some new kinds of things to add to this url that would say what kind of view I want, just the way ours does. So it would generate that and come back and give you a view like that. So it would give you one line--there are other kinds of optional views and etc--so we could start right out exploring and getting people's use. So if other people came to this site and they found something and the you could follow a link, if we could get a switch so that when they go off look at something and we cite them here, then they would get delivered the other view too. A community that started this could start doing that with optional views.
This could go even further, it's like saying this could be a non-HTML file server, so what comes back here is HTML so you can again get the link conventions you're going to use here privately so it comes here, goes back, and calls in some transcoding relationship here. For instance, it would be really fun to say, these are augment files that no one else can read and it comes back here and shows them the structure with all the tag letters and numbers so that becomes something so that when this thing gets a link and says go to that thing and this is the address that I want you to go inside, the address actually isn't there in that original web server but it's there because the interpretation; you've trained this particular way for WBI to do the work and then come back. So it could just open up a whole bunch of OHS stuff that we're trying to do. So then you can even go to a CAD system--this is the sort of thing we were trying to talk to McDonnell Douglass--boy! That would be terrific. You have documentation here that talks about different things about design. Click on a link and you get back a particular extract from the cad system including specifications, if you wish. And they can be in the form of links, too, and you can go and see the actual formal specifications that that thing is being built to. Andrew? ANDREW: This is only an example the marker calls in an operating system uses a technique that instead of giving you back one link, gives you back a number of links that you have norpalopol links that not a part of the existing web. But I guess it's a part of the major process where it says (?) all of the colors you can do that. [nods his head in intense, incomprehensible satisfaction] ENGELBART: Great. And there was another thing that we could do in Augment that was very valuable, and that was indirect linking, which we mentioned before. If there's a link up in server A and it's pointing to a certain reference, I want to go to where that link is pointing. So this thing goes there, gets this thing, comes back, goes here and comes back and gives it to me formulated.
So there are many things that are not in the current environment in what you could do with web stuff that you can start experimenting with. What you would need to do is get the conventions for what WBI can do about it and get the conventions for how you put the request in here. And that's just the sort of thing that the standards like XML, and so forth, are interested in. So to get a body of users to start saying, let's get a coherent application area here going and experimenting with this and the evolution with it I think--would that be nice to have or would it be scary? [laughter] There are other things. Tanya is going to come up next and talk about the Crick system that's being experimented. This is a way to start harnessing back links; and that's been since the 70's. We could never get the resources to start do it at a time like that but if you have in a database a way to collect who's pointing to whom and what kind of typing they're putting on, where do their links go, etc, then that database could answer for you, I'm looking at this document at this certain place, who's pointing at it, I'm on a certain subset of the population with what classes of typing on the links that point to it and I want to see them. And if a certain type has a comment on it, then I'd like to show that in a given window. So that's the sort of thing that you could agree on with WBI, and another thing would be databases being stored in it. So these are things that might want to be explored and I just think that would add a huge amount of value in the world. That's the kind of push for OHS that I'm interested in person-- also the idea that you could get smart agents working for you. What a nice place to introduce them and get them to start working for you; and that's the kind of thing that we're going to ask Adam Cheyer to come, because he's been working in that for a long time, and talk to you. Next we have Tanya Jones, yes, it is an exotic name. That named scared me for a while until I found out she's just a nice girl. Don't change the spelling. She's the staff member at Foresight, and she says she has an official title there. The Foresight Institute is the pioneering one pushing nano technology; it's just great to have you here, so Tanya Jones, you're on the air. Foresight web enhancement by Tanya Jones, Staff member of the Foresight Institute and a supportive volunteer on the OHS planning team I bet she fooled you too. [laughter] OK. So this is beginning to get
some dynamics that I really like because what we're talking about is how
to get a dynamic repository that starts to collect these kinds of things
and then starts integrating to be better at collecting these kinds of things
--that's the bootstrapping, see. And then from all this you can say, hey
Jerry Glen, you can get a better and better picture of what's available
for you to choose for what you're going to do. And not that we're trying
to say that that's what you should do, but give you a chance to make a
decision.
Anyway, just a brief thing to acknowledge that the WWW Consortium and
the XML activity is a very important one and we're really lucky to have
John Bozak here with us, so this is our salute to you, John [salutes] for
coming. The next one is saying, I'm just going to introduce you to the
world right here because he's going to sit there and be part of our panel
discussion later and you ought to know whom it is. We didn't plaster him
with the job of making a presentation. He couldn't, but anyway, he's been
the XML architect at Sun Microsystems and I gather he started the whole
XML movement and is the current leader of the working group of the WWW
Consortium on this. So he gave me these URLs here that will be available
on the slides so that people can look at them. And someday these things
will be able to go out there and they'll be some sort of clickable HTML
sort of things first which we'd be able to recognize like that. [New Slide]
So just what's publicly visible at the WWW Consortium draft recommendations
and the best site for XML information happens to be at the oasis group,
so that's good to know. [www.oasis-open.org/cover/] so that's all for you
to follow.
Anyway, in the environment of OHS we're know that we're going to start learning how to integrate smart AI modules we call agents. And people were telling me in the '60s that I shouldn't be letting things be so hard that the computers were going to get so smart that it would be able to figure out what you knew and you would be able to interface with it at your level. So I said, oh, that's great, but meanwhile the picture that I have about it is that people and the smart agents are like a team. If they're trying to work towards supporting what the human needs, then the humans have got to learn things about how best to harness this team. So they can be very smart aliens and etc and they're just panting to learn to try to do what you want them to do, but how do you direct them, herd them, keep them, and shape them and stuff like that. So I don't see them as removing work from us. It's more of a challenge in fact, than the kind of things where we can start really refining what we do. But they're sitting there as an interface, sort of, support for you; it's a very rich thing. I actually think that it will call for new levels of sophistication in how we humans think and work. I really keep rejecting this idea of automating things. So anyway, the challenge is really harnessing things effectively, and we are really lucky to have this guy named Adam Cheyer, who is currently the Director of Research at VerticalNet in Palo Alto, and who previously was, for many years, a researcher in SRI's Artificial Intelligence Center. And one of the things he innovated was quite notable: this "Open Agent Architecture," which is getting a lot of acclaim in areas of people who understand it better than I do, so I won't go into that. But I like him anyway. So Adam Cheyer is going to come and tell you something about open agents and OHS. Agents, Open Agent Architecture, and Open Hyperdocument System by Adam Cheyer, Director of Research, VerticalNet, Inc., Palo Alto, Ca. Dialogue ENGELBART: There's 14 minutes or so of airtime; so we can have some dialogue that we can share with the world and we can go beyond that a little bit too. One of the things that I'd like to get as soon as we can is if anything can aim at John Bozak about XML, just give him a chance. Do you want to say anything at the start? JOHN BOZAK: Yeah, I do. I'm supposed to be alive for this thing--I'm told I am alive. That's good to know. You wouldn't know, really. [laughter] I'm really delighted to see a concrete proposal. One of the reasons I'm delighted is because the organizer promised me in a few weeks I'd be able to propose something which, if it has any reality at all, which is still open to debate, would need this [OAA] to exist. So this is great; I'm real happy to see this and we'll get to that when we get to it. There are some aspects of this that work only because of the very careful way things have been narrowed down. For example: "Create schemas and translators" is like a black hole, unless you've restricted it to just the four things you've listed--that works--you can actually do that. I think that the capabilities are well done and I think that most of the hardcore choices are actually the right choices. I don't know enough about WebDav to be able to endorse that. [But] I do know of nothing else in that space, so I'm hoping that's the right thing. I do very much like the idea of doing something with Apache. I would push that hard. Those of you who have been following XML would know that Apache has just a huge wedge of XML code donated to it and a whole set of XML tools is being standardized under the Apache umbrella. IBM contributed a big chunk of it, Sun contributed some of it, Lotus contributed some of it, and there were some other contributors. So you're getting a whole set of interoperable open source, publicly available XML tools and I think the suite of tools you talk about would fit very nicely into that. So the organization: I like the way you're going. I love it. That's basically what I have to say about that. Now I should also say that I don't have a presentation on purpose. It wasn't that I failed to make one but I was told that we didn't want one this time. I would be happy if the organizers want to, sometime between now and the end of the series, to put together a presentation for you about XML and existing standards that will be helpful if we decide to go down this road and get into that. I mean, no problem. That is not a problem. I told Doug, give me a week and I'll put together anything you want. I did post to the list a URL-- which is slightly too long to read, it went out to the one list--of a 4-hour tutorial on this subject I gave last June from the University of California, if I could say that here. [laughter] it wasn't Berkeley; it was SC, so it's all cool--very cool! So I put that on the list and as I said we could do that, and beyond that I probably shouldn't say anything or else I'll start talking an hour and a half on this subject. But I'll be glad to answer questions if there are any at that. ENGELBART: So let's have some open dialogue; it's you and you. RICHARD: Well, Doug mentions integrated editing and browsing. Do you mean when you're browsing, you hit a button and then you get the XML source code? Or is that not sufficient; do you edit the same exact rendered view that you browse in? ENGELBART: Sure. RICHARD: How do you do that in XML? You've got XSL, for example that is designed to only go in one way. CHEYER (seated): In this proposal my accommodation was the XML editor would be a separate sort of ugly tree thing, and I didn't find a good way to do it yet in the existing model and to do a truly integrated WYSIWYG editor/browser there are some out there. However, I think to do it in a fairly general way would be kind of hard. So this is a very general accommodation I took that would let any browser participate and then we'll just have to figure out how to merge them better. ENGELBART: I'd say that we had a principle that whatever editing you're allowed to do in any view was real and it made a change that the other views would recognize appropriately and etc. It seems to me that that's the way humans need it. AUDIENCE: There is some excellent work being done at Georgia Tech on this by cohorts Alan Kay and Mark Guzdyle (sp?). It's called a [swickie] and it's based on Squeak, which is the open source Smalltalk that spun out of Apple a few years back. And they've been doing a lot of experiments, not only about what the interface should be like, but also what are the social consequences of anybody being able to modify anything when you are browsing it. It's very interesting work. BOZAK: Yeah, there are two critical aspects to make the editing work here. Editors are a bitch. It's just true. And the whole process of editing is a nightmare, regardless of XML. But the thing that makes this work is that we're not talking about generic, unlimited numbers of document types, we're talking about the 4 that are listed. So what we're really talking about is four different editors, one for stuff that's stored as email, one for stuff that's stored as HTML, one for stuff that's stored as Augment, and one for stuff that's stored as source code. This is believable. If you get into a generic editor, there are only two companies in the entire world that are making generic commercial XML editors and they charge you $500 to $1000 a seat, and quite rightly. So your question is well taken; it's a hard problem generically. We can do it with these four by having XSL style sheets that work with at least one company's existing browser, sort of, well enough to make the concept to work. The really hard part that I can think of as long as we stick to just these four document types is the version control. And the check in and checkout. That's going to be difficult. RICHARD: There are selectable views. I think that Doug considers it essential that you have multiple views and have found a number of different ways to view the same document. Is that correct? And that seems to be the big thing that you can't have that and editing at the same time. That's the hardest thing to get. BOZAK: Uh, you can have that and editing at the same time, but I don't think that you'd want to. The other aspect of this was wysiwyg. wysiwyg is a strange concept, and if you examine it carefully it tends to fall apart and get away from you like a cloud of butterflies. I don't want to make WYSIWYGishness a hard requirement if only because we could we spend the next six months trying to define by what we mean by it. However, being able to do a reasonable job of editing content--there is a concept called WYSIWYN, which is "What You See Is What You Need." In other words, it's close enough to be making the visual distinctions that you're relying on to get a kind of implied logical structure which is what people usually mean when they say, "I want WYSIWYG." You can get that without getting into fine detail into typography. ENGELBART: Let's give Andrew a chance--he's got to go back to Australia afterwards. ANDREW: Yeah, I've got a short point I'm answering and one long point --I'll answer the short one first. The Web Consortium's official test bed for this stuff is at Meyer. Which, I'm amazed, no one has mentioned because it is, in fact, an integrated browser/editor which already does HTML and has very rapidly had a lot of XML support added. AUDIENCE: And is open source. ANDREW: And is open source, exactly. The long point was that this is, I think, a great venue, this colloquium, and I really hope that we have more of this kind of thing because hopefully we'll get more cross-pollination because I have attended and tried in my role with Ted on the Xanadu Project. I've attended ITF working groups, I've been a member of the WebDav group, the hypermedia conferences and the hypertext conference series, Foresight Institute with Ping on the quick stuff; I'm a member of the Amaia project and I'm on a whole lot of mailing lists and across a whole lot of projects and working groups and I'm seeing a whole little wheel reinventing and almost everyone who is doing this stuff is not aware of the other projects. There's a lot of this stuff that I've seen done before that have been done by the other groups. Most of this kind of work has emerged since 1999, really, and there are groups in Europe, groups in England, groups in Austria, groups in Finland, groups in Japan, doing these kinds of things and there's not enough cross-pollination. For example, OHS also stands for the Open Hypermedia System Working Group which is a series of meetings of both the hypertext conferences and also at web consortium and digital libraries conferences to try and provide an integrated common point of reference for all these sorts of projects so that they can talk to one another so that instead of people building each new project every time at their own little university and not being able to share any of the data, there can be hopefully one day be some way where we can be able to take all the good work that's already been done by people building these kinds of projects and then kind of interconnect them. ENGELBART: Okay. So do we have any other new blood coming in or does our panel want to respond? CHEYER: I just wanted to say one word. I am aware of Amaia, and its counterpart Jigsaw. I was looking at do we need to have a stand alone, separate integrated browser and editor. And looking at Amaia, it still seemed that in order to bring sort of Doug Viewing and to do these 4 goals, it still looked like there was a lot of work left to do. It seems to do math ml and HTML pretty well and it's on the right path but it's still pretty far so this proposal was that any browser could start to play and the editor/browser part will evolve later. ANDREW: Yeah, let me refine my eloquent--I'm not suggesting that you should not do what you're doing. I'm not suggesting that at all because as you rightly point out Amaia would perhaps be a quick solution to get something that's already been written but ultimately you'd want to go beyond that, and that's very positive. And I certainly think that any group that is aware of previous work in the fields and is extending it and has legitimate reasons to develop additional tools is terrific. But there are a lot of projects there where people have done earlier research and it's being, for example--user interfaces being designed to address some of these issues --and hardly anybody seems to track down any of these projects and obtain copies of the software and look at it and learn what can be learned from it and learn what can be integrated. That was really my point, not that you shouldn't be doing what you were doing. I think that, in fact, you are doing the right thing by allowing people with any browser to use it. ENGELBART: That's terrific Andrew, and we started out earlier talking about what we really knew. You have to start collecting information and assessing it about what's the state of things--we call that the sea level work. And we'd really like to get a group going that can build a repository of that and etc. and be part of evolving through bootstrap. So I'm very pleased to hear about all of this and let's see. We're going off the air in about 5 seconds, so is there anything anybody particularly wanted to say on the air? Go ahead. AUDIENCE: [inaudible] Thank you, I'm very-- AUDIENCE: Oh, sorry, I wasn't on the mike. Happy birthday to Doug on Sunday! ENGELBART: Yeah, I'm going to be a grown up. [Laughter] okay. AUDIENCE: Perhaps it was me but I think I noticed an energy change as that list was being introduced to us and I think it got a lot of people's excitement up as well it should and I like the list. I think that for some set of requirements it is clearly the right list. What I found myself reacting to is not being sure what the requirements were. Now, the first goal says "capabilities" and one could say, well, the requirement would be to do those things. Now that may be sufficient for many situations, especially research environments, creating them and then maybe later worrying about how we're going to use them is exactly the right approach. For a large, diffuse, loosely connected, unfunded kind of activity, very often defining the problem that you want to solve, in the killer app sense, where the end user isn't one of the geeks but is going to try to do some real work and would love to have whatever this is could do would be extremely helpful. So I would like to suggest--and I don't have a proposal for what exactly that should be--but except to propose that it should be something. ENGELBART: Thank you. ERIC ARMSTRONG: Eric Armstrong. I have a requirements document on the online One list mailing server and hopefully we can start to modify that but there needs to be some things cut down from this proposal which would be great and would make it more feasible and more things added, but you're absolutely right; requirements are the first step. AUDIENCE: I should clarify. The nature of this kind of thing is to say, "What can we do soon" and really walks a different tightrope, which is exactly the right kind of thing. And equally there is a different requirement on the requirement and that is: which of the requirements is interesting, useful, and near-term that we can achieve doing this. ENGELBART: What's your name to tell people? DAVE CROCKER: Dave Crocker. ENGELBART: That sounds familiar. The Crocker family that was involved --how many years ago that it was that we met? CROCKER: 28. ENGELBART: [chuckle] Yeah. Thank you, Dave. CROCKER: I needed help to get a demo going for the first demonstration of the AARPANET and knew that the people at SRI were very friendly and that was the system I was using. And I found that there was only one name attached to the SRI system at that time and it was Doug. And I had never met him and I was not even a graduate student at that point. But I knew they were friendly people so I asked him for some help and he said, "Where are you?" And I said, "Well, I'm in Washington getting ready for a demo" and he said, "Where are you?" And it turns out he was about 20 feet away from me. [laughter] ENGELBART: Yeah, it's a small world and you must be almost getting to be a grown up too. [laughter] well, just because we're off the air doesn't mean we need to stop. There's something about the staff here that they aren't chartered here to stay and keep this open forever but if you want to keep dialoguing, I think that's just terrific. All I say is, when you do focus on something and get going, let me come along with you. [laughter] You know, for there they go. So are there any more things about this? Okay, Dick? RICHARD KAZPINSKI: I wanted to say in particular that I heard in the last 20 minutes several of instances of commercial organizations contributing to a freely shared output, and I would like the people who are close to that to see if they could come up with any of the things that permitted that to happen. Permitted IBM and Sun and Cisco to contribute software and effort into a common thing. ENGELBART: Yes I agree with you and what strikes me is that I'd like to get a record of the kind of things have been said here. Anyways, if anyone were taking any notes of this, this would be valuable. Assumedly, we dream at times of getting it all transcribed [Transcriber's note: <grin>] and interlinked or something. [Someone mentions something about going out for burritos.] Okay. [applause, and I guess everyone went out for burritos.]
---
Above space serves to put hyperlinked
targets at the top of the window
|

 Fig.
1
Fig.
1 Fig.
2
Fig.
2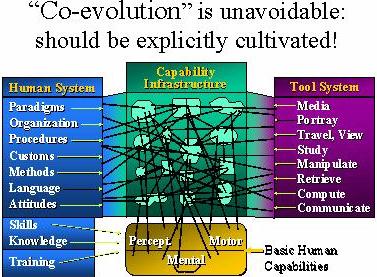 Fig.
3
Fig.
3 Fig. 4
Fig. 4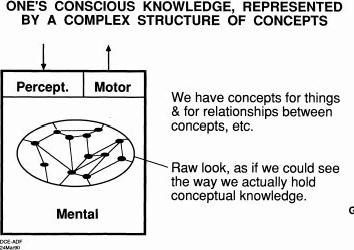 Fig. 5
Fig. 5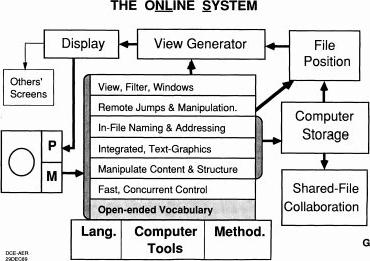 Fig.
6
Fig.
6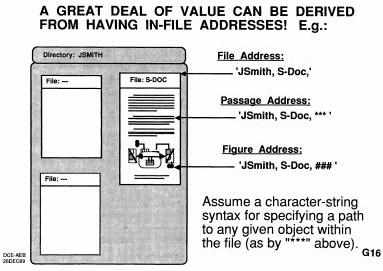 Fig.
7
Fig.
7
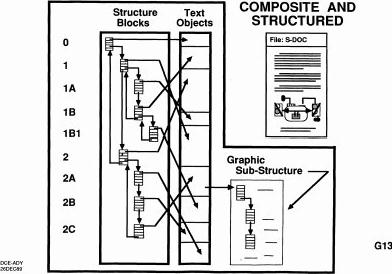 Fig.
8
Fig.
8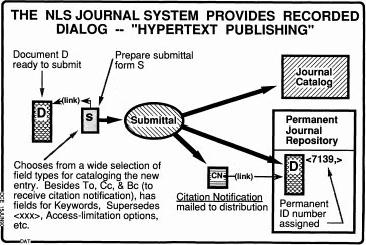 Fig.
9
Fig.
9 Fig.
10
Fig.
10 Fig.
11
Fig.
11
 Fig.
12
Fig.
12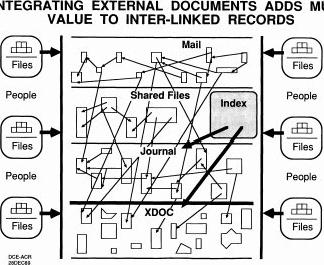 Fig.
13
Fig.
13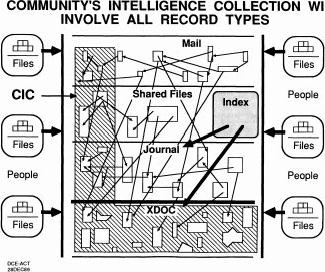 Fig.
14
Fig.
14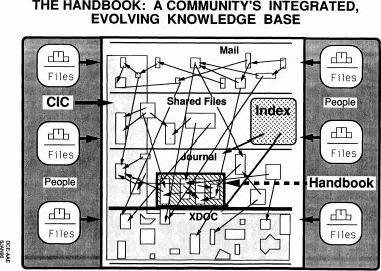 Fig.
15
Fig.
15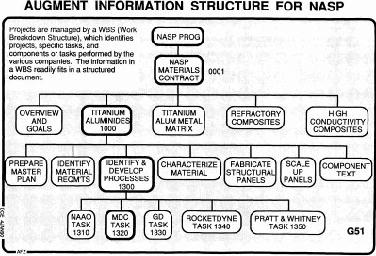 Fig.
16
Fig.
16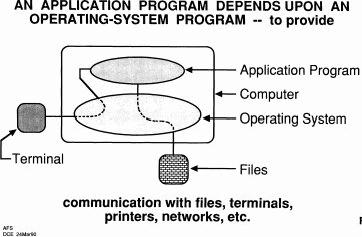 Fig.
17
Fig.
17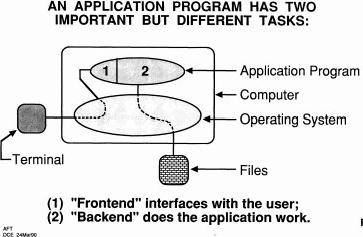 Fig.
18
Fig.
18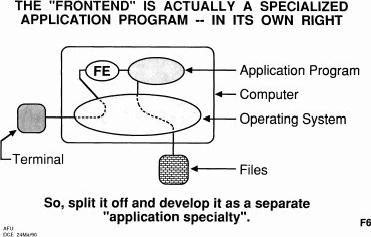 Fig. 19
Fig. 19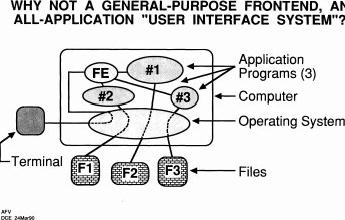 Fig.
20
Fig.
20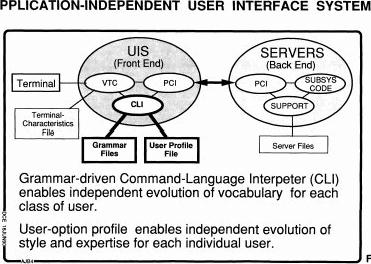 Fig.
21
Fig.
21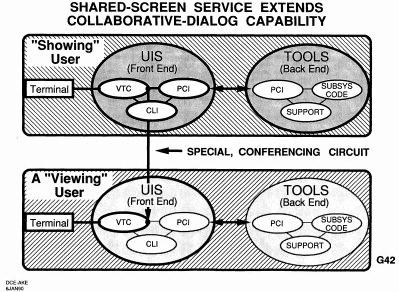 Fig.
22
Fig.
22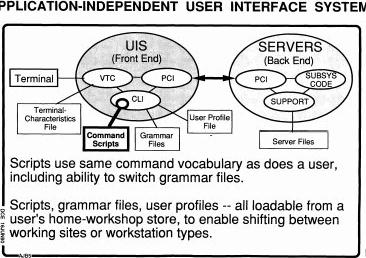 Fig.
23
Fig.
23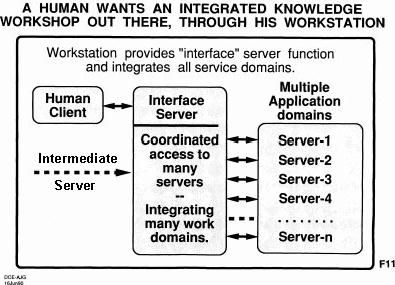 Fig.
24
Fig.
24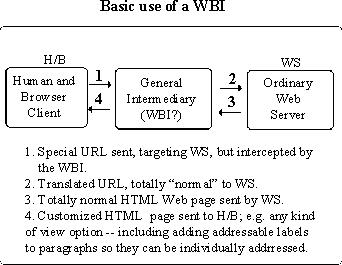 Fig.
25
Fig.
25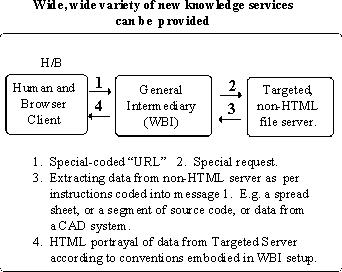 Fig.
26
Fig.
26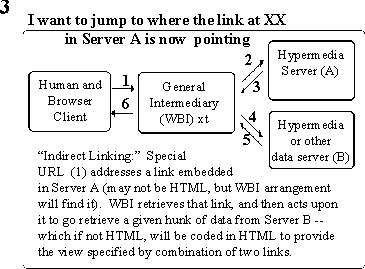 Fig.
27
Fig.
27